@莫凯洁:现代汉语词汇语体属性探测模型研究
【摘要】本文立足于正式—非正式的语体维度,提出了基于机器学习方法的现代汉语词汇语体属性探测模型,旨在实现符合语体连续统特性的词语正式度测量。研究首先构建了现代汉语语体语料库,设计了语体分类特征,并基于《现代汉语词典》(第7版)中的〈书〉〈口〉标注数据训练语体属性自动分类模型。模型五折验证准确率达87.26%。进一步的误例分析发现:词典中的语体标注存在部分缺漏、过时、不对称等问题,而基于语体语料库的语境特征能有效修正数据偏差。为了更好地服务词汇语体教学,本研究使用上述模型对《国际中文教育中文水平等级标准》词表和《义务教育常用词表(草案)》主表的共25500个词语进行了语体正式度测量,并分析了该方法在词典编纂和教学方面的应用。
引言
- 语体是不同交际演域中具有差异的语言体系,承载着人类语言的社会性,在人类交际中起着重要作用。
- 前人研究中存在问题:从正式—非正式范畴来看,语体的过渡呈现为一个连续统(崔希亮,2020),而仅靠语感难以实现对连续统的精确描述。
- 目前标注词语语体的方法主要有以下三种
- 人工标注
- 从典型语料中提取高频词
- 对比词语在典型语料中的频度
- 本研究目标:采用机器学习方法,构建现代汉语词汇语体属性探测模型,为词典编纂和汉语教学提供支持。
语料库构建
- 词汇数据
- 《现代汉语词典》(第7版)(以下简称《现汉》)中标注了口语体词和书面文言词汇。
- 从《现汉》中提取标注〈口〉的口语体词838个,标注〈书〉的书面语词3002个,并随机抽样2500个不带任何语体标注的通用体词汇。最终,从《现汉》中得到非正式语体词汇3338个,正式语体词汇3002个,其比例为1.1:1,
- 语料库
- 分为两类:
- 正式语体:公文、学术文章、政论、新闻报道。
- 非正式语体:小说、散文、微博、歌词、谈话、问答。
- 语料来源:百度百科、学术文章、新闻报道、小说、微博等。
- 语料预处理:分词、词性标注、语义标注等。
- 分为两类:
模型构建
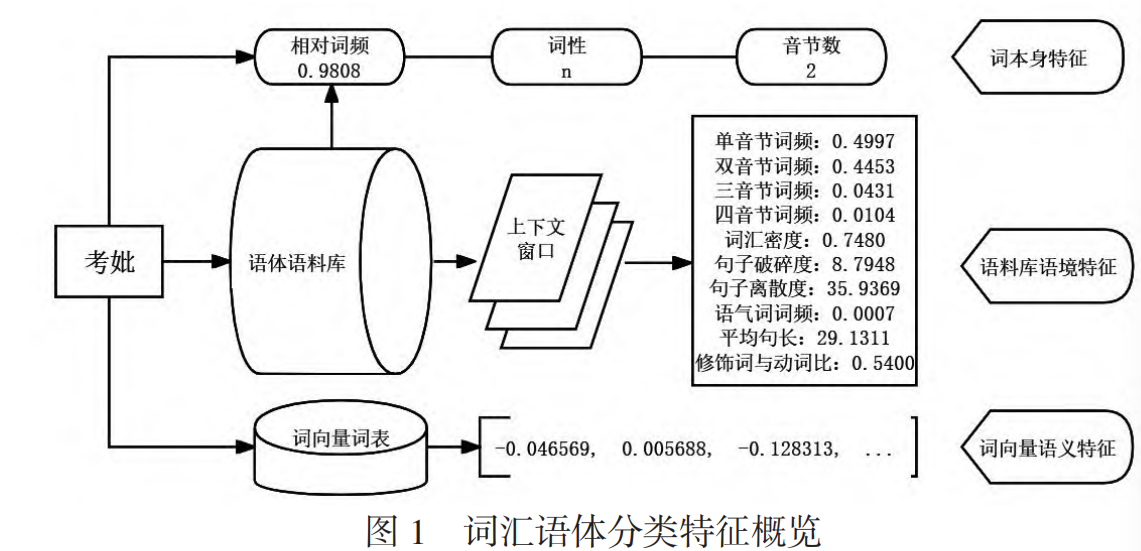
- 词本身特征
- 音节数、词性以及词语在语体语料库中的相对词频。
- 相对词频
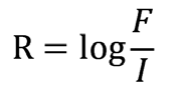
- 其中,F为词语在正式体语料库中的词频,I为该词在非正式体语料库中的词频。例
- 语料库语境特征
- 本研究提取目标词的前400字和后400字作为上下文窗口,获得目标词的所有上下文窗口后进行随机抽样,使每个目标词上下文窗口数量保持在3000个以内,最后将所有上下文窗口所取文本合并成语境文本。
- 词音节信息:分别统计语境文本中单音节、双音节、三音节、四音节词所占比例。
- 修饰词与动词比:反映文本的描写性和修饰性,数值较高表明文本语言生动,具有文学性;反之,则文本说明性强,话语较平淡(邰沁清、饶高琦,2021)。
- 词汇密度:指语境文本中的实词比例。
- 句子破碎度:统计语境文本中总字数除以句中因断句而停顿的次数。
- 句子离散度:统计语境文本中每个句子的句长偏离平均句长的程度,即句长的总体标准差。
- 语气词词频:语境文本中的语气词频率(语气词数量/总词数)。
- 平均句长
- 基于词向量的语义特征
- Li等(2018)在中文混合语料库(涵盖新闻、百科、问答、微博等语料,共15G)上训练的词向量作为语义特征
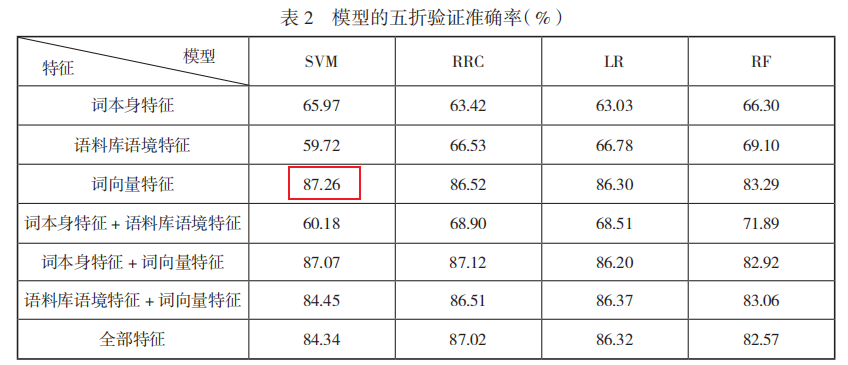
研究将正式-非正式维度的词汇语体属性分析问题建模为二分类任务,使用多种机器学习模型构建分类器开展实验,包括支持向量机(Support Vector Machine,SVM)、岭回归分类(Ridge Regression Classifier,RRC)、随机森林(Random Forest,RF)和逻辑回归(Logistic Regression,LR)。
实验与结果
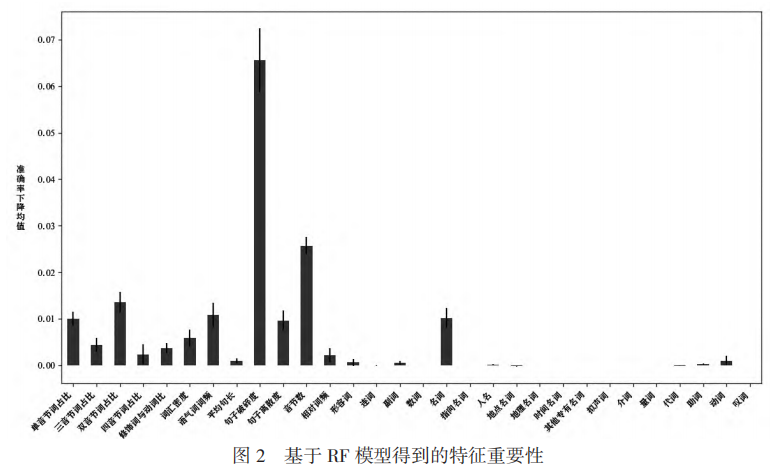
为探测词本身特征和语料库语境特征的重要性,实验使用特征排列法计算了各个特征的重要性分数。RF模型(词本身特征+语料库语境特征训练)使用特征排列法后得到的各个特征重要性。
误例分析
- 标注遗漏
- 标注过时
- 标注不对称
模型误差校正
词向量特征的 svm 模型,容易存在“文言偏见”,即“一个词语越接近文言表达,正式度越高”。
可以引入RF模型(词本身特征+语料库语境特征)来矫正训练数据中的“文言偏见”。
词表语体属性预测
《国际中文教育中文水平等级标准》词表语体属性预测
《义务教育常用词表(草案)》主表语体属性预测